数据可视化
pandas绘图
线图
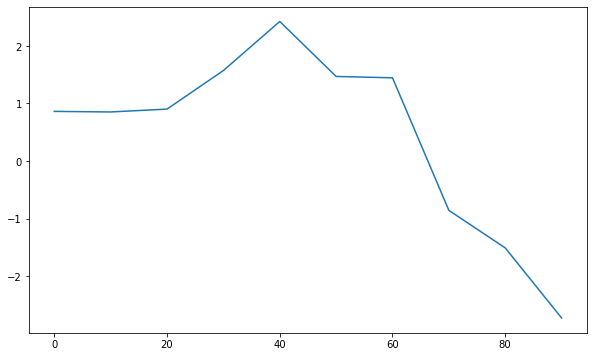
Series 和 DataFrame 都有一个用于生成各类图表的 plot 方法。默认情况下,它们所生成的是线型图:
>>> s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
>>> s
0 0.862580
10 0.852548
20 0.902558
30 1.572773
40 2.425738
50 1.469869
60 1.446376
70 -0.857858
80 -1.510327
90 -2.728629
dtype: float64
>>> s.plot()
tip
该 Series 对象的索引会被传给 matplotlib,并用以绘制 X 轴。可以通过 use_index=False 禁用该功能。X轴的刻度和界限可以通过 xticks 和 xlim 选项进行调节,Y轴就用 yticks 和 ylim。
plot方法参数
| 参数 | 说明 |
|---|---|
| label | 用于图例的标签 |
| ax | 要在其上进行绘制的 matplotlib subplot对象。如果没有设置,则使用当前的 matplotlib subplot |
| style | 将要传给 matplotlib 的风格字符串(如'ko--') |
| alpha | 图表的填充不透明度(0到1之间) |
| kind | 可以是 line、bar、barh、kde |
| logy | 在 Y 轴上使用对数标尺 |
| use_index | 将对象的索引用作刻度标签 |
| rot | 旋转刻度标签(0到360) |
| xticks | 用作 X 轴刻度的值 |
| yticks | 用作 Y 轴刻度的值 |
| xlim | X 轴的界限(例如[0,10]) |
| ylim | Y 轴的界限 |
| grid | 显示轴网格线(默认打开) |
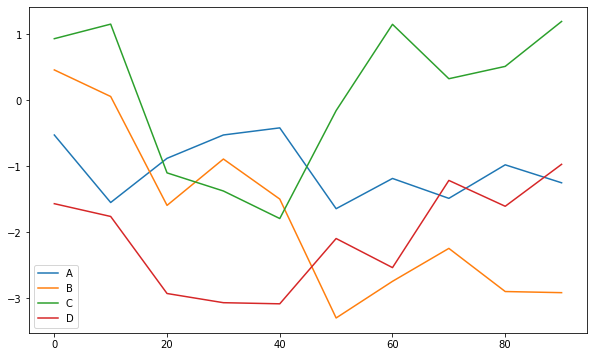
DataFrame 的 plot 方法会在一个 subplot 中为各列绘制一条线,并自动创建图例:
>>> df = pd.DataFrame(np.random.randn(10, 4).cumsum(0),
columns=['A', 'B', 'C', 'D'],
index=np.arange(0, 100, 10))
>>> df
A B C D
0 -0.528735 0.457002 0.929969 -1.569271
10 -1.551222 0.054175 1.150456 -1.762672
20 -0.882063 -1.594810 -1.102342 -2.929504
30 -0.528456 -0.892700 -1.376911 -3.068646
40 -0.420799 -1.499245 -1.793975 -3.085653
50 -1.644944 -3.300085 -0.159239 -2.096645
60 -1.187004 -2.744930 1.147481 -2.537198
70 -1.488355 -2.246139 0.323490 -1.216633
80 -0.980390 -2.899577 0.510469 -1.608358
90 -1.252683 -2.916718 1.190790 -0.972845
>>> df.plot()
柱状图
>>> data = pd.Series(np.random.rand(16), index=list('abcdefghijklmnop'))
>>> data
a 0.779728
b 0.721451
c 0.310442
d 0.363083
e 0.196082
f 0.935492
g 0.561734
h 0.817292
i 0.348914
j 0.799714
k 0.104104
l 0.712120
m 0.917448
n 0.803585
o 0.327113
p 0.255107
dtype: float64
>>> fig, axes = plt.subplots(2, 1)
>>> data.plot.bar(ax=axes[0], color='k', alpha=0.7)
>>> data.plot.barh(ax=axes[1], color='k', alpha=0.7)

tip
color='k' 和 alpha=0.7 设定了图形的颜色为黑色,并使用部分的填充透明度。
对于 DataFrame,柱状图会将每一行的值分为一组,并排显示:
>>> df = pd.DataFrame(np.random.rand(6, 4),
index=['one', 'two', 'three', 'four', 'five', 'six'],
columns=pd.Index(['A', 'B', 'C', 'D'], name='Genus'))
>>> df
Genus A B C D
one 0.370670 0.602792 0.229159 0.486744
two 0.420082 0.571653 0.049024 0.880592
three 0.814568 0.277160 0.880316 0.431326
four 0.374020 0.899420 0.460304 0.100843
five 0.433270 0.125107 0.494675 0.961825
six 0.601648 0.478576 0.205690 0.560547
df.plot.bar()

caution
DataFrame 各列的名称 "Genus" 被用作了图例的标题。
设置 stacked=True 即可为 DataFrame 生成堆积柱状图,这样每行的值就会被堆积在一起:
>>> df.plot.barh(stacked=True, alpha=0.5)

tip
柱状图有一个非常不错的用法:利用 value_counts 图形化显示 Series 中各值的出现频率,比如s.value_counts().plot.bar()。
假设我们想要做一张柱状图以展示每天各种聚会规模的数据点的百分比。用 read_csv 将数据加载进来,然后根据日期和聚会规模创建一张交叉表:
>>> tips = pd.read_csv('examples/tips.csv')
>>> party_counts = pd.crosstab(tips['day'], tips['size'])
party_counts
size 1 2 3 4 5 6
day
Fri 1 16 1 1 0 0
Sat 2 53 18 13 1 0
Sun 0 39 15 18 3 1
Thur 1 48 4 5 1 3
# 去除1人聚会和6人聚会,因为次数很少
>>> party_counts = party_counts.loc[:, 2:5]
>>> party_counts
size 2 3 4 5
day
Fri 16 1 1 0
Sat 53 18 13 1
Sun 39 15 18 3
Thur 48 4 5 1
# 数据归一化
>>> party_pcts = party_counts.div(party_counts.sum(1), axis=0)
>>> party_pcts
size 2 3 4 5
day
Fri 0.888889 0.055556 0.055556 0.000000
Sat 0.623529 0.211765 0.152941 0.011765
Sun 0.520000 0.200000 0.240000 0.040000
Thur 0.827586 0.068966 0.086207 0.017241
>>> party_pcts.plot.bar()

info
通过该数据集就可以看出,聚会规模在周末会变大。